Autómatas y lexers
orden del día:
- Repaso de DFA
- DFA de ejemplo
- Ejercicio de DFA de ejemplo #1
- Ejercicio de DFA de ejemplo #2
- Ejercicio interactivo de DFA #1
- Ejercicio interactivo de DFA #2
- Intervalo
- Lexers
- Ejemplo de lexers
- Generador de lexers: flex
Cómo visualizar un DFA
$(\Sigma,D,T,S_0,A)$
El siguiente DFA detecta un número impar de letras a.
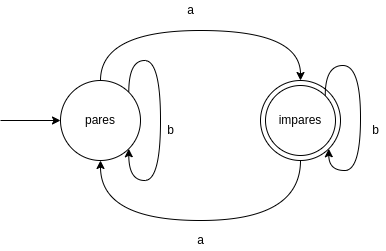
A continuación se describe el mismo DFA sin un diagrama.
- Alfabeto $\Sigma=\{a,b\}$
- Conjunto de estados $D=\{pares, impares\}$
- Estado inicial $S_0 = pares$
- Estados de aceptación $A={impares}$
- Función de transición $T:D\times\Sigma\rightarrow D$: tabla a continuación
| estado | letra | nuevo estado |
| $pares$ | $a$ | $impares$ |
| $pares$ | $b$ | $pares$ |
| $impares$ | $a$ | $pares$ |
| $impares$ | $b$ | $impares$ |
Lexers
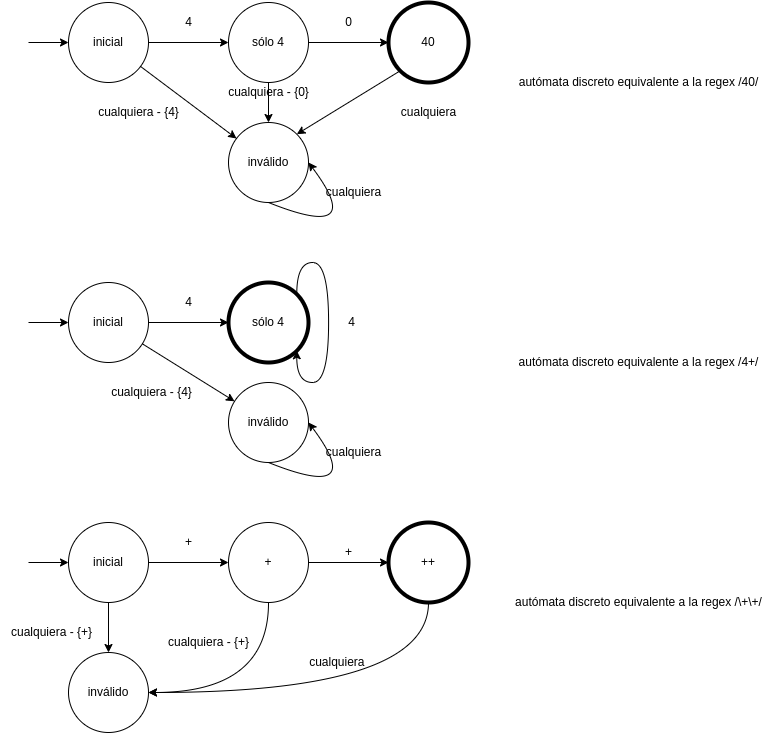
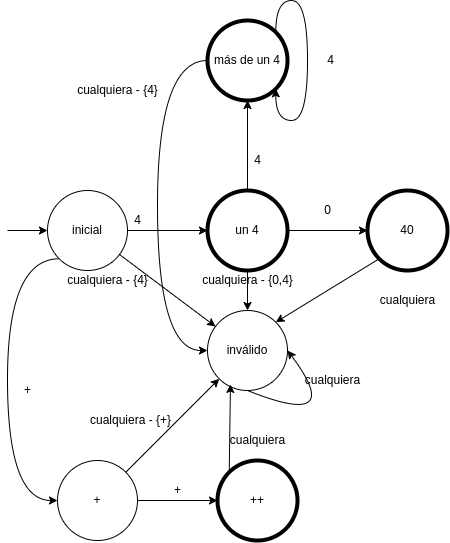
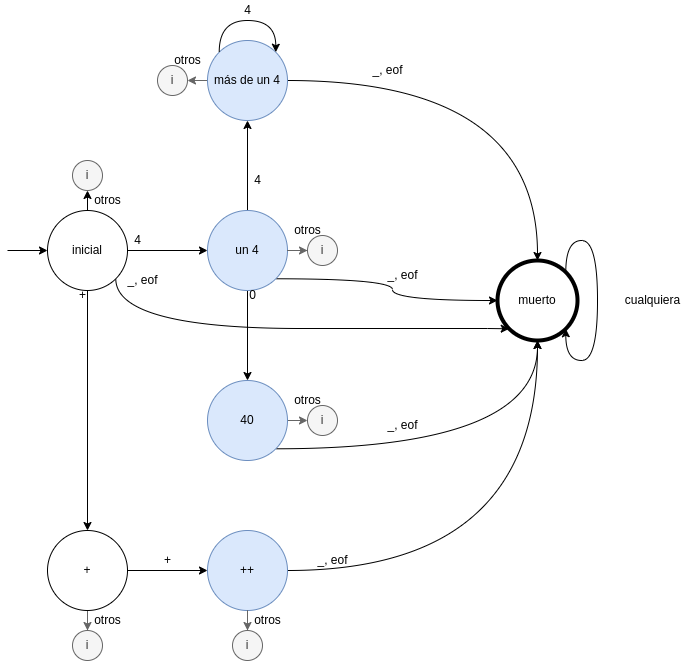
Nuevos tipos de estado:
- Estado inicial: separado
- Estado tokenizable
- Estado inválido
- Estado muerto
¿Preguntas?
¡A trabajar!