Laboratorio 4: Resumen teórico
Bibliografía#
Louden 4.2, 3.2. Ullman 4.2.1. Apuntes de la teórica.
Definición de gramática libre de contexto#
Una grmática libre de contexto se define matematicamente como:
- Conjunto de símbolos terminales (
if,int,{... ) - Conjunto de símbolos no terminales (
IfStmt,VarDecl,BlockExpr) - Conjunto de producciones (
BlockExpr -> { CompoundStmt }) - Un símbolo inicial
Una gramática es una 4-upla:
Notación#
En el laboratorio 3 y el laboratorio 4 se usa la siguiente notación:
- Simbolos no terminales: encerrados por
< >por ejemplo, el símbolo llamado expresión se representa como<expresion> - Símbolos terminales: sin una notación particular. El literal if se escribe
if. - Producciones:
- El símbolo no terminal que da lugar a la producción se escribe del lado izquierdo
- El símbolo utilizado es
::=en vez de una flecha - Los símbolos que tiene como resultado la producción van del lado derecho de
::=
Derivaciones#
Consisten en transformar el símbolo inicial aplicando producciones sucesivas.
Grmáticas ambiguas#
Son aquellas que permiten llegar a cierta una secuencia de símbolos a través de distintas secuencias de aplicación de producciones. Las gramáticas ambiguas permiten interpretar el código de más de una forma, con lo cual no son utiles.
Gramáticas LL1#
Las gramáticas LL1 son aquellas que:
- No tienen recursividad por izquierda
- No son ambiguas
Las grmáticas LL1 se pueden utilizar facilmente en parsers LL1.
¿Qué es un parser LL1?#
Un parser LL1 es similar al parser descendiente recursivo pero usa un stack explícito donde el parser recursivo descendiente utiliza el call stack.
"Partes" de un parser LL1:
- Cola que contiene la secuencia de simbolos que se debe parsear. El parser unicamente lee de aquí, no hace push.
- Stack de estado: Contiene la información que antes tenía el call stack
- Tabla de transiciones M: Tabla de doble entrada . Esta tabla se usa cuando hay un símbolo no terminal en la punta del stack de estado. A partir del no terminal del stack de estado () y el primer terminal de la cola (), define qué producción () aplicar.
- "nucleo algorítmico" descripto acontinuación.
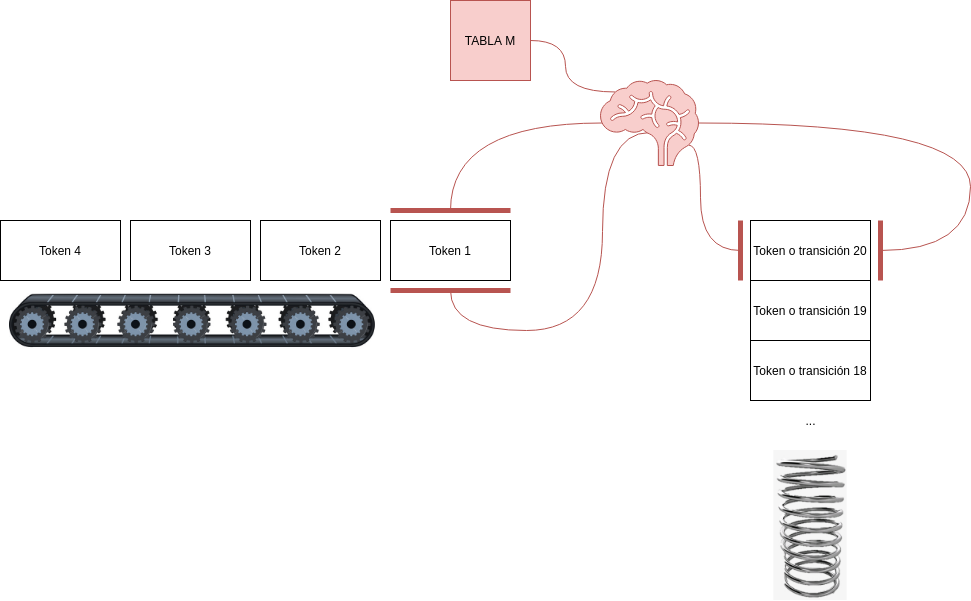
Algoritmo de un parser LL1#
stack_estado=[símbolo_inicial]cola=listado_de_tokenswhile len(cola) > 0: if cola[0]==stack_estado[0]: cola.pop() stack_estado.pop() else: produccion = M[stack_estado[0],cola[0]] stack_estado.push(*produccion.lado_derecho)A fines del laboratorio, escribimos el algoritmo de la siguiente manera:
stack_estado=[símbolo_inicial]cola=listado_de_tokensdef match(): cola.pop() stack_estado.pop()def apply(produccion): stack_estado.push(*produccion.lado_derecho)
while len(cola) > 0: if cola[0]==stack_estado[0]: match() else: apply(M[stack_estado[0],cola[0]])En los ejercicios de parsing LL1 del presente laboratorio, se debe describir el listado de operaciones match y apply que realizaría el parser LL1.